Building a Technical Support Bot: Lessons from the RAG Design
I’ve recently had the pleasure of being part of a team building an internal technical support bot. The mission was twofold:
- Outsmart the generalists: Know the company’s (and related providers’) technical ecosystem better than any third-party provider
- Supercharge the field: Provide multiple tools that support our field team in their day-to-day work.
It was an intense 6-8 weeks getting to an alpha version for internal testers. While I can’t share the exact proprietary “secret sauce,” the journey of building a production-grade system led to several experiments and discoveries that I believe are valuable for anyone building a retrieval system today.
A Brief History (and Reality Check) on RAG
By now, most of us are familiar with RAG (Retrieval-Augmented Generation). A year ago, it was the buzzword of the moment. Now it’s still commonly used, but more common grounds have been established.
Essentially, we want LLMs to have “fresh” knowledge or deep expertise in specific domains they weren’t trained on—think internal product docs or niche legal frameworks. These aren’t in the public corpus, and since models are fixed in time, they lack “yesterday’s” updates.
Early on, many thought post training of the LLM was the answer. However, as I shared in my previous post, Fine-Tuning Lessons from the Trenches, training is a delicate, expensive process. I am no means an expert in LLM training but the fun exercise taught me how hard it is. For most knowledge-retrieval tasks, fine-tuning is overkill.
RAG won because it’s modular: you give a well-trained LLM a “library” (a vector index) and the tools to go find the right book. If you’re using an internal tool at work that actually knows your company’s product, there’s almost certainly a RAG pipeline behind it.
Deep Dive: The Mechanics of Modern RAG
A simplified RAG flow looks like this:
- Ingest: Store data sources (internal documentation).
- Chunk: Break them into digestible pieces.
- Retrieve: When a question is asked, perform a similarity search to find the top X chunks.
- Augment: Feed those chunks to the LLM to generate a grounded answer.
The “magic” (and the frustration) is in the details. Small decisions here drastically affect quality and latency.
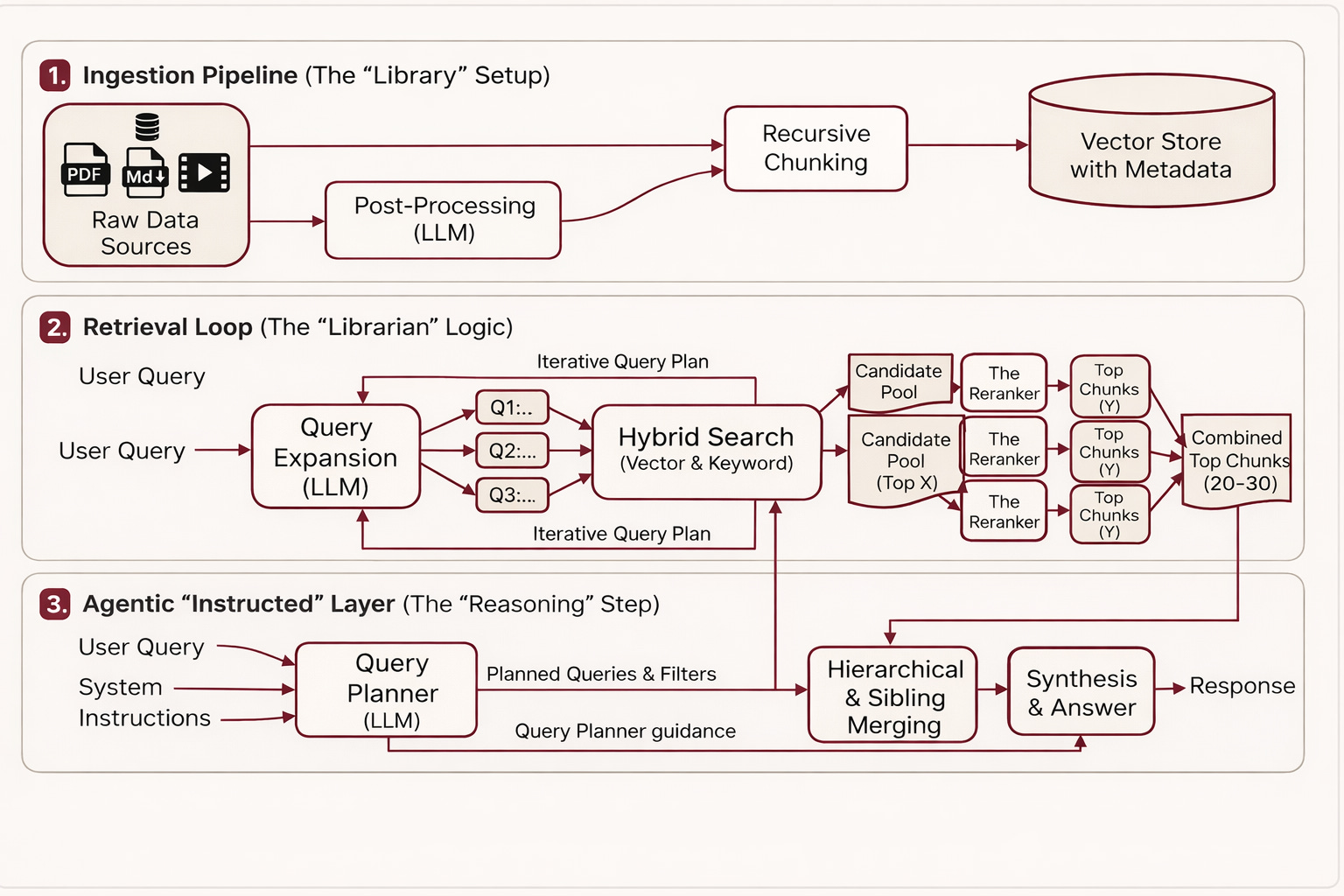
Part I: Data Processing & “The Noise Problem”
1. The Chunking Strategy
You have to define how you “slice” your data. It’s a balancing act:
- Too Big: If your chunks are massive (e.g., 5,000 words), and you pull the top 3, you risk “dilution.” The LLM gets a lot of irrelevant fluff surrounding the one paragraph it actually needs.
- Too Small: If you pull 20 tiny snippets, you lose context. It’s like trying to understand a movie by looking at 20 random frames.
The Logical Cutoff:
Commonly, we use a recursive split strategy. We look for natural breaks like paragraphs first; if a paragraph is still too long, we fall back to sentences.
Example: Imagine a technical spec. A recursive splitter will try to keep a “How-To” step intact as one chunk. If that step is 2,000 characters, it stays together. If it’s 10,000, it breaks it down at the sentence level so the LLM isn’t overwhelmed by a single “wall of text.”
Metadata tends to be missed out: Don’t just store text. Store attributes like product_version, cloud_provider, or doc_type. I’m using my technical bot as the example here, but this applies everywhere.
Example: If you’re building a bot for AWS, GCP, and Azure, you want the flexibility to filter by “provider” before you even search. This prevents the bot from giving an Azure solution to an AWS question just because the semantic “similarity score” was high. It turns a probabilistic guess into a deterministic filter.
2. Hybrid Search & Rerankers
Standard vector search understands intent (e.g., “dancing like a butterfly” → searching for agility, not insects). But sometimes, you need old-school keyword search. If a user searches for a specific error code like err_0402_x, a vector search might get “close,” but a keyword search finds this directly if you have the info.
The Reranker: This is now very common as well. You might pull 50 potential chunks via hybrid search, but then you use a smaller, faster model (the Reranker) to score those 50 and pick the absolute best 5 to show the LLM.
3. Solving the “Signal-to-Noise” Ratio
Not all sources are created equal. Video transcripts or roundtable interviews are notoriously “low density”—lots of “umms,” “ahhs,” and tangents. Many of us watch a fairly decent 1 hour youtube 1-1 interview, but you were to summarise for someone you really can do that in 10 mins worth of good notes.
- Tip: Use an LLM to “process” these. Ask it to clean the transcript, keeping 60% of the core content but structuring it into clear bullet points. This turns a messy 20-minute chat into a high-signal knowledge chunk.
Part II: Retrieval Logic
4. Beyond Individual Chunks: Hierarchical & Sibling Merging
In a standard RAG setup, you usually just feed the LLM the specific snippets that matched the search. But in a complex technical environment, a single snippet is often like a single puzzle piece—you can’t see the whole picture.
To solve this, one approach is to implement a merging logic to reconstruct the context:
- Hierarchical Merging (Parent Retrieval): If our search finds multiple small chunks that belong to the same section, we don’t just send those fragments. If a parent document or section appears more than X times in our candidate pool, the system “upgrades” the retrieval to fetch the entire Parent Chunk. This gives the LLM the full technical context of that specific module or procedure.
- Sibling Expansion: Sometimes the answer isn’t in the matched chunk itself, but in the paragraph right before or after it (the “siblings”). If we find a high-affinity chunk, we automatically pull its Sibling +1/-1 chunks. This ensures that if the user asks “How do I do X?”, and the match is the middle of a numbered list, the LLM actually sees the “Prerequisites” and “Warnings” mentioned in the surrounding text.
Tip: Think of this as “Contextual Reconstruction.” You want to move from providing matching snippets to providing meaningful sections. It drastically reduces the “I don’t have enough information” errors from the LLM.
Part III: Advanced Retrieval Logic
The “standard” way—Top 5 chunks → LLM—works if your docs are perfect. But they rarely are.
Query Expansion
Sometimes the user doesn’t know how to ask the right question. We found Query Expansion to be highly effective. We ask the LLM to generate 3-4 variations of the user’s question to “cast a wider net” in the vector database.
Example:
User Question: “How do I fix the latency in my table query?”
Expanded Queries:
- “Optimizing Table Query performance.”
- “Troubleshooting slow read/write in Spark.”
- “Best practices for file skipping.”
The “Instructed Retrieval” Approach
Scaling is the ultimate challenge. If you have 50 different use cases, you don’t want 50 sets of rigid RAG rules. This is where Instructed Retrieval comes in (a January 2026 Databricks release, recommend read).
Instead of a fixed “Search Top 5” rule, you give the LLM the autonomy to decide how to search based on system-level instructions. The “Instructed Retriever” (specialised small model or the frontier models) translates natural language into a structured Search Plan. It can decide to apply a SQL-like metadata filter for “recency” or “product version” before it even looks at vector similarity. It bridges the gap between the “vibes” of semantic search and the “rules” of enterprise data.
- The Trade-off (Latency): This adds time. You are doing 1 question → Search Planning → Multi-step Retrieval → Synthesis. However, for complex support, quality beats speed. If the question is hard enough that a senior engineer is asking the bot (and not just checking a general tool like ChatGPT or Claude), they are willing to wait even minutes for a thorough, correct answer rather than get a “hallucinated” fast one that they have to verify themselves.
Closing Thoughts
Focusing on the RAG process is just the beginning. How you wire these results into an agent that can actually execute tasks—like drawing an architecture diagram or checking a live API—is a whole other massive area to tackle.
If there is one takeaway from these 8 weeks, it’s this: The quality of your retrieval determines the ceiling. You can have the smartest model in the world, but if you feed it garbage chunks, you’ll get “smart-sounding” garbage out.