From Sequential to Router Agents: Three Architectures for Agent AI Systems
The Evolution Journey
Building an endurance coaching AI that adapts training plans in real-time sounds straightforward—until you realize quality recommendations require multiple specialized analyses: zone physiologist (updating training zones), training load analyst (calculating TSS/ATL/CTL metrics), recovery analyst (interpreting HRV and sleep data), and a master coach synthesizing everything into actionable adaptations.
The challenge: How do you orchestrate these specialized perspectives efficiently without sacrificing quality?
Over an extended period, I evolved through three distinct architectures, each solving different constraints as the system matured. This post shares the cost-quality trade-offs, architectural decisions, and when each approach makes sense.
The three phases:
- Sequential Agent - Blocking handoff between specialists (MVP)
- Multi-Agent - Parallel execution with specialized agents (Growth)
- Orchestrator (Router) - “Deep Agent” inspired unified router (Scale)
Let me share what I’ve learned.
Phase 1: Sequential Agent Architecture
What It Was
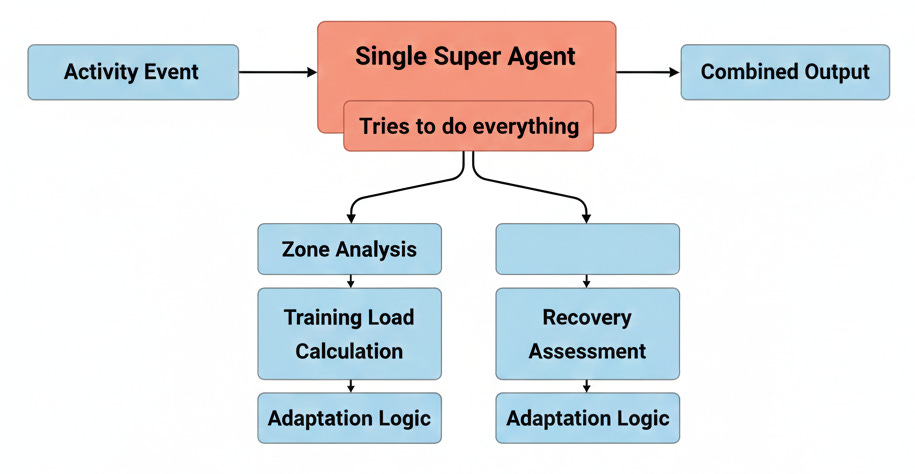
The first implementation was deliberately simple: blocking handoff between agents in a linear pipeline.
Flow: Zone Physiologist → Training Load Analyst → Recovery Analyst → Master Coach
Each agent waits for the previous one to complete before starting. Results flow linearly through the pipeline.
Why Sequential Made Sense for MVP
The case for simplicity:
- Fast to implement (no orchestration framework needed)
- Easy to debug (linear execution, clear data flow)
- Low cognitive overhead for the team
- Sufficient for early validation (8.4s acceptable at low volume)
For MVP, sequential was the right choice. Ship fast, validate product-market fit, optimize later.
When It Broke Down
As usage grew, the real problem wasn’t just speed—it was depth.
The “Single Coach” Limit: Think of a single coach trying to support a Tour de France rider. That coach has to be a physiologist, a nutritionist, a mechanic, and a tactician all at once. Context switching reduces quality. The agent defaulted to generic, “safe” answers rather than deep, specialized insights. It struggled to judge when to use specific tools (e.g., specific RAG retrievals for complex injury history).
Performance Problem:
- 8.4s user-facing latency was noticeable, but manageable.
- The bigger issue was that for 8.4s of wait time, users expected expert-level depth, but often got generalist advice.
Decision: To get Tour de France quality, we needed a Tour de France team—specialized agents working in parallel.
Phase 2: LangGraph Multi-Agent Orchestration
The Architectural Shift
As multi-agent patterns like LangGraph and Supervisor architectures began to emerge, they offered a clear path to better quality: specialization.
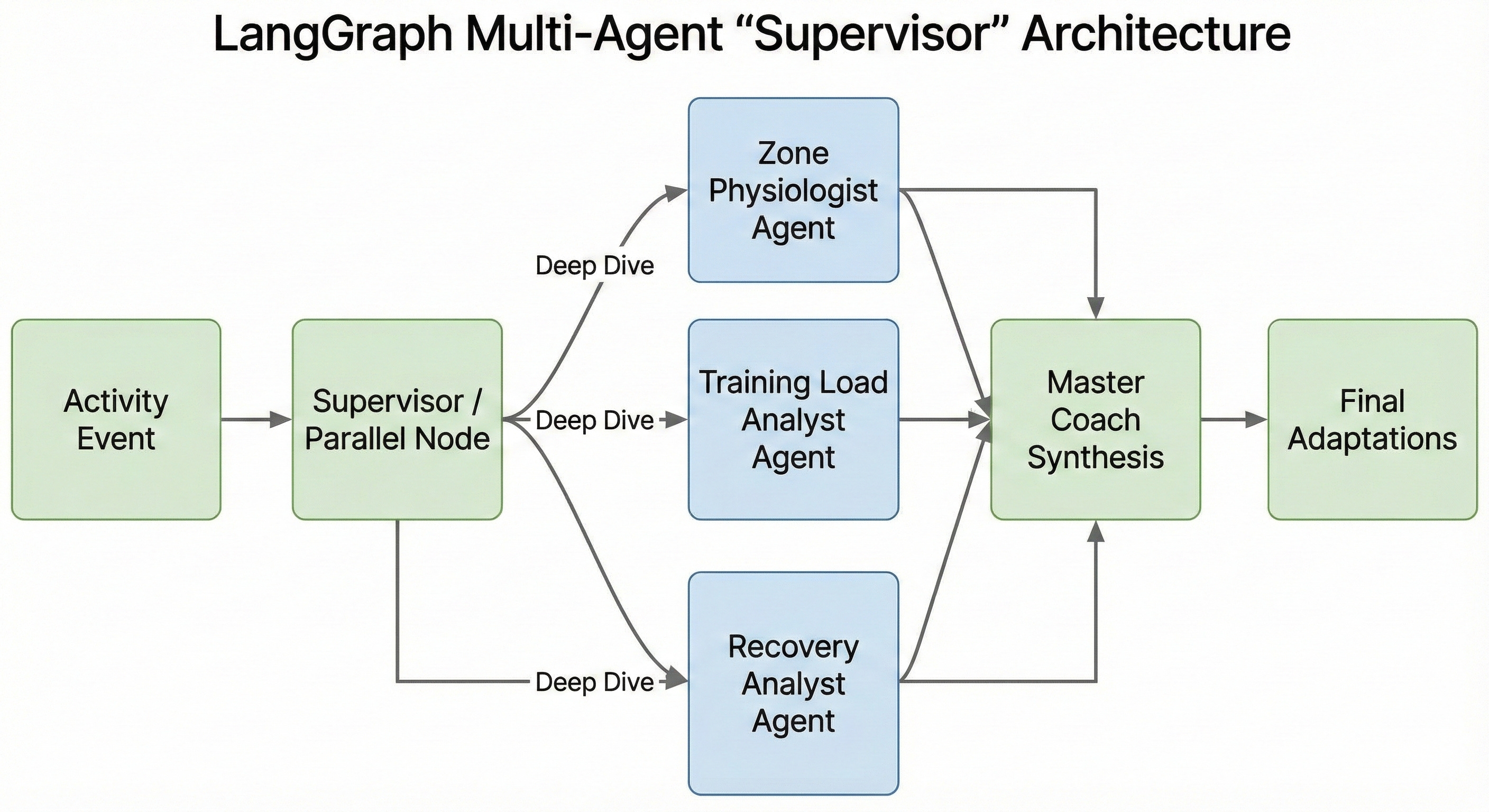
We moved from a generalist model to a “Supervisor” approach:
- Parallel execution of specialised agents (Zone, Load, Recovery)
- Shared state for results
- Supervisor node aggregating insights
The Challenge: Cost & Overkill
Technically, this worked beautifully. The quality of advice skyrocketed because each agent had a specific prompt, specific tools, and specific RAG context.
But the cost was unsustainable. Imagine convening a full medical board review for every scraped knee.
- Overkill: We were running full multi-agent committee meetings for every single workout update—multiple times a day.
- Token Bloat: ~10,200 tokens per orchestration.
- Redundancy: 90% of the time, the recovery analyst would just say “Recovery looks fine, no changes needed.”
The system was too rigid. It treated a routine Tuesday run with the same heavyweight process as a complex injury return plan.
Phase 3: Unified Router with “Deep Agent” Inspiration
The Optimization Challenge
We needed the depth of the multi-agent system but the efficiency of a single agent for routine tasks.
The Core Innovation: “Call as You Need”
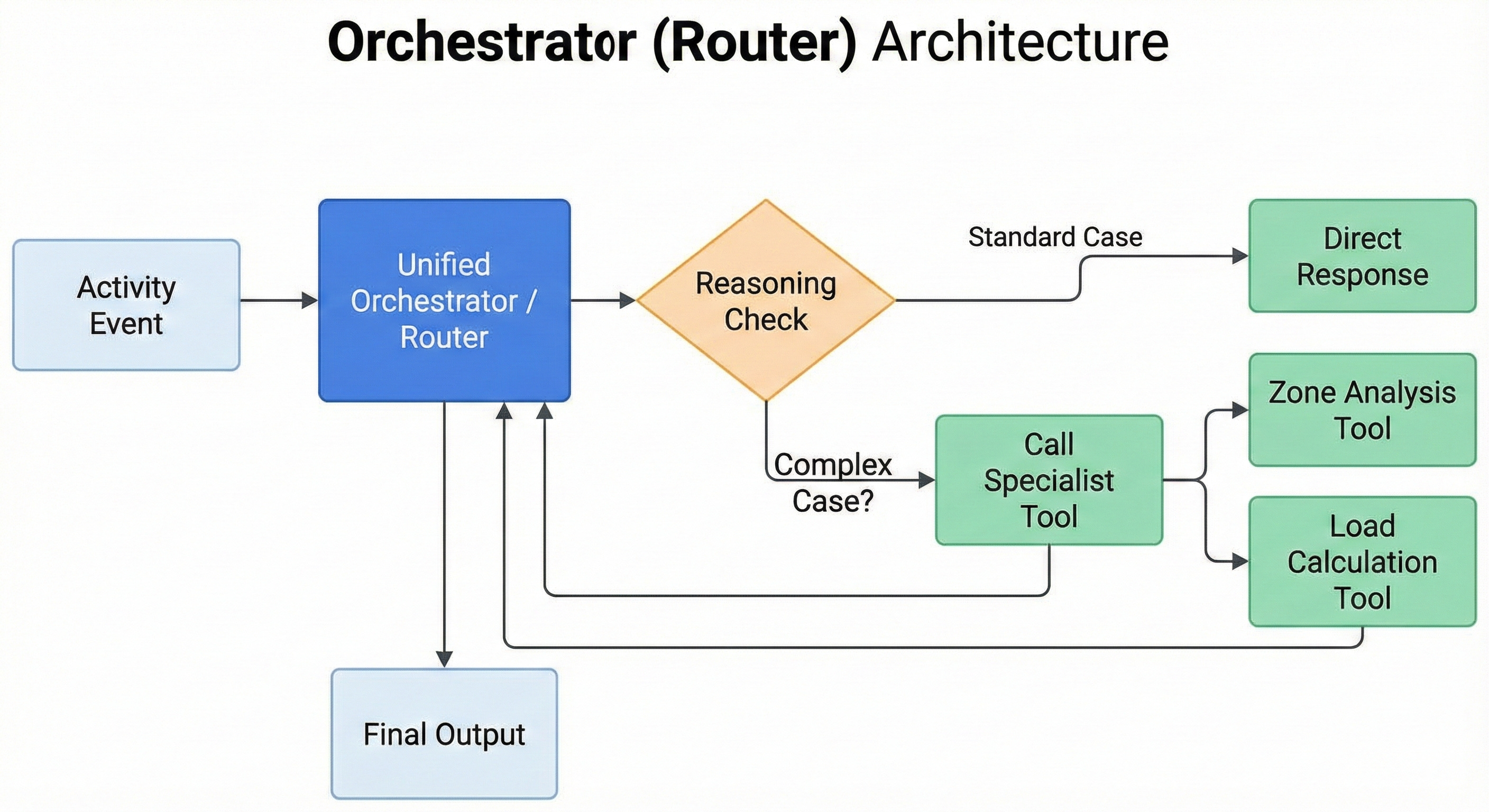
Inspired by emerging “Deep Agent” research, we flipped the model. Instead of a fixed pipeline, we built an intelligent Orchestrator (Router).
The Orchestrator acts like a triage nurse or a team director. It sees the data first and decides: “Do I can handle this myself, or do I need a specialist?”
- Unified Orchestrator: First pass analysis.
- Intelligent Routing: “Is this a complex zone drift issue? Call the Zone Physiologist tool. Is this just a normal run? Handle it.”
- Dynamic Tooling: Specialists became tools or sub-routines rather than mandatory stops on a train line.
Why This Wins
It balances the “Tour de France Team” capability with practical efficiency.
- Routine Day: Orchestrator handles it. Cost: Low. Speed: Fast.
- Complex Day: Orchestrator calls in the team. Cost: Higher. Speed: Slower (but worth it).
This “Call as you need” pattern allows the system to be as simple as possible but as complex as necessary.
Cost-Quality Trade-offs: The Full Picture
Comprehensive Comparison
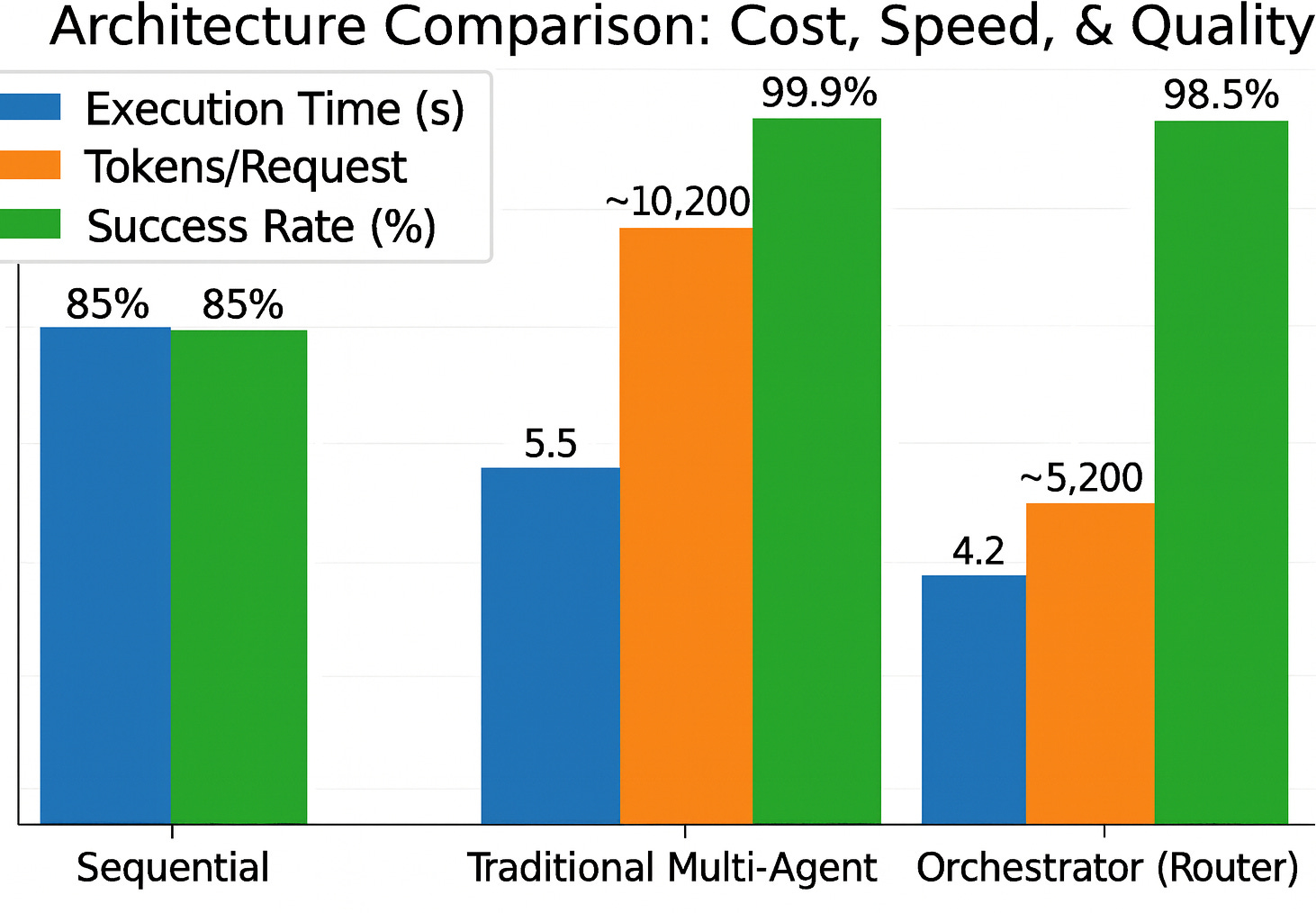
The verdict: 49% cost reduction, 24% faster, with <2% quality impact. Acceptable trade-off for production at scale.
Closing
There’s no universally “best” multi-agent architecture. The right choice depends on the objective and constraints.
Each phase was the right architecture for its constraints:
- Sequential for MVP speed
- Traditional Multi-agents for quality and reliability
- Orchestrator (Router) for cost efficiency at scale
The key is recognising when constraints change—and evolving the architecture accordingly.